— 【科技实话】AI本地应用,双向奔赴但道阻且长 —
更新时间:2024-03-10 16:05:03 编辑:丁丁小编






永久可坐可躺遛娃神器手推车【优惠券:满338元减90元】
永久遛娃神器手推车宝宝可坐可躺可睡儿童轻便折叠婴儿双向溜娃车领券购买

ROMOSS罗马仕22.5W2万毫安充电宝【优惠券:满99元减11元】
罗马仕自带线充电宝双向快充20000毫安大容量便携户外出行移动电源适用于小米oppo华为苹果iPhone14官方正品领券购买
本文转载于:https://www.sohu.com/a/763143735_223764 如有侵犯,请联系dddazheyh@163.com删除
热门文章榜
-
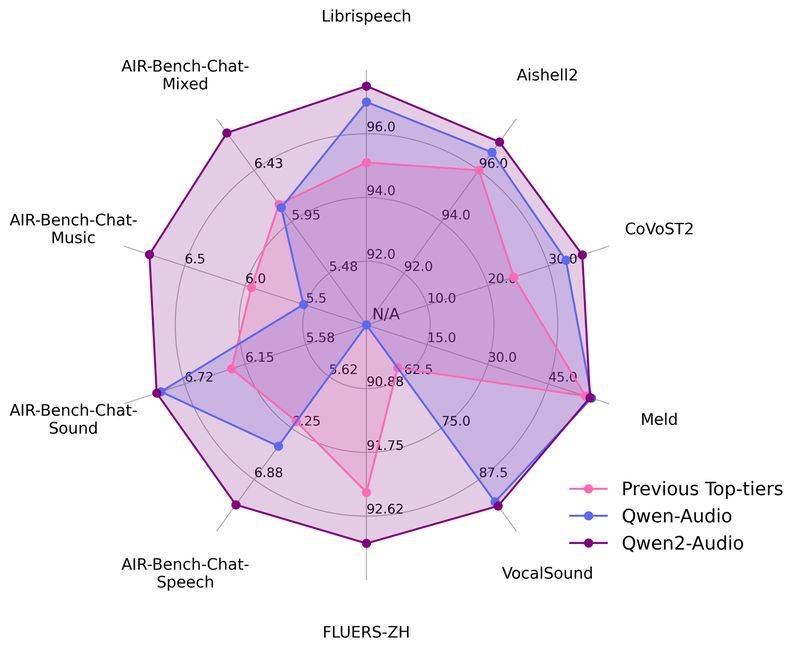
- 阿里通义千问开源新一代音频语言模型 支持语音聊天且内容精准度更高
- 阿里通义千问开源新一代音频语言模型 支持语音聊天且内容精准度更高
- 立即抢购
-

- 适合学生党的性能长续航手机,就选这三款“卷王”
- 适合学生党的性能长续航手机,就选这三款“卷王”
- 立即抢购
-

- 三星研发QD-OLED面板量子点墨水再生技术 有望降低设备成本和售价
- 三星研发QD-OLED面板量子点墨水再生技术 有望降低设备成本和售价
- 立即抢购
-

- 高通骁龙8Gen 4将搭载自研CPU 首发双版本其一或为高性能版
- 高通骁龙8Gen 4将搭载自研CPU 首发双版本其一或为高性能版
- 立即抢购
-

- 就是“一句话的事儿!” 荣耀先于苹果发布AI Agent
- 就是“一句话的事儿!” 荣耀先于苹果发布AI Agent
- 立即抢购
-

- 华为Watch GT5将采用新传感器技术 有望快速准确监测多项健康数据
- 华为Watch GT5将采用新传感器技术 有望快速准确监测多项健康数据
- 立即抢购
热门优惠券
更多-
 立即领取
立即领取Debenhams UKExtra 15% Off Selected Brands
Debenhams UKExtra 15% Off Selected Brands -
 立即领取
立即领取Serenata FlowersFlash Sale | Get 16% Off The Joyful Wishes Bouquet – was £34.99, now £29.39
Serenata FlowersFlash Sale | Get 16% Off The Joyful Wishes Bouquet – was £34.99, now £29.39 -
 立即领取
立即领取京东商城英氏官方旗舰店满20减13
京东商城英氏官方旗舰店满20减13 -
立即领取
京东商城沐林旗舰店满29减23
京东商城沐林旗舰店满29减23 -
立即领取
京东商城六神京东自营旗舰店满35减12
京东商城六神京东自营旗舰店满35减12
最新分享
更多-
 立即阅读
立即阅读一加13首销半小时即破10万台!高配版本占比80%
2024-11-01 17:05:01 -
 立即阅读
立即阅读顶级国产屏!「全能旗舰」一加13实在太香了
2024-11-01 16:15:02 -
 立即阅读
立即阅读两大影像旗舰同台竞技:OPPO Find X8 Pro和vivo X200 Pro怎么选?
2024-11-01 16:10:01 -
 立即阅读
立即阅读iQOO 13战报出炉!首日销量破iQOO新机纪录
2024-11-01 16:05:02 -
 立即阅读
立即阅读双11想换护眼显示器?千元档首选华为MateView SE
2024-11-01 15:05:04 -
 立即阅读
立即阅读AI商务笔记本新标杆:dynabook TECRA A40-M
2024-11-01 13:05:02 -
 立即阅读
立即阅读从龙之信条2到黑神话,为什么如今的大型单机越来越吃内存CPU?
2024-11-01 12:15:02 -
 立即阅读
立即阅读探秘科沃斯擦窗宝:轻松搞定“高空”难题!
2024-11-01 12:10:02 -
 立即阅读
立即阅读科沃斯T50 PRO扫地机器人:智启未来,清扫无界,让家焕然一新
2024-11-01 12:05:06 -
 立即阅读
立即阅读一加13「超Pro」性能体验:全面流畅才是检验性能的标准
2024-11-01 11:10:05