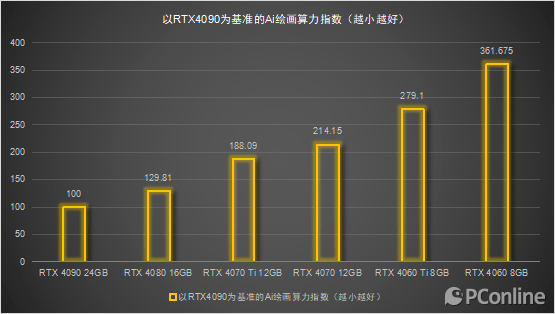
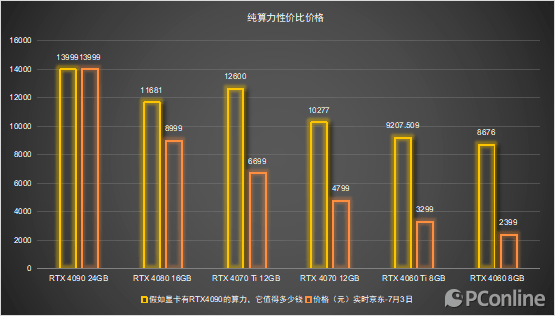
— 【Ai时刻】什么?你的显卡还只用来打游戏?—NVIDIA RTX 40系列显卡Ai算力横评 —
更新时间:2023-07-04 10:09:55 编辑:丁丁小编


















mag卵磷脂猫牛磺酸爆毛粉维生素【优惠券:满39元减20元】
MAG卵磷脂猫牛磺酸颗粒爆毛粉猫掉毛吃什么美毛猫软磷脂猫咪专用领券购买

文明接亲小游戏道具创意房堵门拦门【优惠券:满2元减1元】
接亲小游戏道具创意晨袍拍照氛围结婚礼堵门文明搞笑全套闯门套餐领券购买
本文转载于:https://www.sohu.com/a/694113740_223764 如有侵犯,请联系dddazheyh@163.com删除
热门文章榜
-

- 富士GFX 100SII,GF50mmF3.5,亿级像素下的越南足迹
- 富士GFX 100SII,GF50mmF3.5,亿级像素下的越南足迹
- 立即抢购
-

- 新年装机好时机,内存就选金泰克
- 新年装机好时机,内存就选金泰克
- 立即抢购
-

- 颜值音质两手抓!Cherry HW2.2耳机体验:价格不贵用着舒坦
- 颜值音质两手抓!Cherry HW2.2耳机体验:价格不贵用着舒坦
- 立即抢购
-

- 手办自由就在今天!AI 帮你 60 秒生成 3D 模型
- 手办自由就在今天!AI 帮你 60 秒生成 3D 模型
- 立即抢购
-

- AMD或推RX9000M系列移动显卡 基于Navi44/48两种核心架构
- AMD或推RX9000M系列移动显卡 基于Navi44/48两种核心架构
- 立即抢购
-

- 手机厂家争先恐后接入DeepSeek,是因为自家AI不行吗?
- 手机厂家争先恐后接入DeepSeek,是因为自家AI不行吗?
- 立即抢购
热门优惠券
更多-
 立即领取
立即领取CasetifyUse Code: MemberSale25 - Save Up to 25% Gold, Silver- Buy 2 get 25% off / Bronze, New, Basic
CasetifyUse Code: MemberSale25 - Save Up to 25% Gold, Silver- Buy 2 get 25% off / Bronze, New, Basic -
 立即领取
立即领取ShopbopShop Up to 25% Off Your Order of $200 or More with Code STYLE
ShopbopShop Up to 25% Off Your Order of $200 or More with Code STYLE -
立即领取
CasetifyUse Code: SpringSale25 - Buy 2+ Get 20% OFF *Select Markets Only*
CasetifyUse Code: SpringSale25 - Buy 2+ Get 20% OFF *Select Markets Only* -
立即领取
Shopbop3 Days Only: Take 20% Off Select Styles with Code SELECT20
Shopbop3 Days Only: Take 20% Off Select Styles with Code SELECT20 -
 立即领取
立即领取京东商城ROTHSCROOSTER旗舰店满49减16
京东商城ROTHSCROOSTER旗舰店满49减16
最新分享
更多-
 立即阅读
立即阅读给用户的惊喜:华为服务春日礼遇火热进行中,省钱又省心!
2025-05-04 10:32:56 -
 立即阅读
立即阅读为了拯救因 AI“殉情”的青少年,AI 软件决定这样做
2025-05-03 10:18:00 -
 立即阅读
立即阅读Prompt逐步失效!全自动AI模型还有多远
2025-05-02 12:18:00 -
 立即阅读
立即阅读三星和京东方专利官司继续:三星再提诉讼,目标禁售京东方
2025-05-02 03:47:57 -
 立即阅读
立即阅读OLED又有新噱头?三星表示:300尼特的OLED可与500尼特的LCD媲美
2025-05-02 03:32:57 -
 立即阅读
立即阅读进击的京东方:今年出货1.7亿片AMOLED面板,但和三星还有差距
2025-05-02 03:26:57 -
 立即阅读
立即阅读OLED迎来革命性时刻!LGD表示:蓝色磷光OLED将实现量产
2025-05-02 03:20:57 -
 立即阅读
立即阅读RTX 50高端卡供应太惨:海外禁止游客购买,人肉带货都不行
2025-05-02 03:17:57 -
 立即阅读
立即阅读海信海外机型全部发布:RGB Mini LED领衔,基本和国内同步
2025-05-02 03:05:57 -
 立即阅读
立即阅读NVIDIA RTX 50全军覆没?供电区域出现高温点,影响使用寿命
2025-05-02 03:02:57