— Meta推出音频AI模型,仅需2秒即可模拟真人语音片段 —
更新时间:2023-06-21 10:15:00 编辑:丁丁小编




华为mate20钢化mate20pro mt手机膜【优惠券:满7元减1元】
适用华为mate20钢化膜mate20pro手机膜mate20x全屏mete20por贴膜20x5g屏幕meta水凝无白边m20魅特mt保护mata领券购买

华为mate40pro钢化膜保时捷水凝膜【优惠券:满7元减1元】
适用华为mate40pro钢化膜水凝膜mete40保护rs保时捷mt40e手机贴膜m40epro全屏mat40por软膜meta魅特mata全包领券购买
本文转载于:https://www.sohu.com/a/687614115_223764 如有侵犯,请联系dddazheyh@163.com删除
热门文章榜
-

- 适合学生党的性能长续航手机,就选这三款“卷王”
- 适合学生党的性能长续航手机,就选这三款“卷王”
- 立即抢购
-

- 三星研发QD-OLED面板量子点墨水再生技术 有望降低设备成本和售价
- 三星研发QD-OLED面板量子点墨水再生技术 有望降低设备成本和售价
- 立即抢购
-

- 0.02mm精度+百元天花板,玄派X68磁轴键盘键盘来袭
- 0.02mm精度+百元天花板,玄派X68磁轴键盘键盘来袭
- 立即抢购
-

- 高通骁龙8Gen 4将搭载自研CPU 首发双版本其一或为高性能版
- 高通骁龙8Gen 4将搭载自研CPU 首发双版本其一或为高性能版
- 立即抢购
-

- 就是“一句话的事儿!” 荣耀先于苹果发布AI Agent
- 就是“一句话的事儿!” 荣耀先于苹果发布AI Agent
- 立即抢购
-

- 华为Watch GT5将采用新传感器技术 有望快速准确监测多项健康数据
- 华为Watch GT5将采用新传感器技术 有望快速准确监测多项健康数据
- 立即抢购
热门优惠券
更多-
 立即领取
立即领取HeartlandVetSupply.comCompounding Oral Suspension Sale
HeartlandVetSupply.comCompounding Oral Suspension Sale -
 立即领取
立即领取Amazonliss (US)20% off Amazonliss Keratin Treatment Collection
Amazonliss (US)20% off Amazonliss Keratin Treatment Collection -
 立即领取
立即领取Debenhams UKFree next day & express delivery
Debenhams UKFree next day & express delivery -
 立即领取
立即领取Benefit Cosmetics UK35% Off Twinkle Beach Blush & Highlighter Palette, Now Just £15!
Benefit Cosmetics UK35% Off Twinkle Beach Blush & Highlighter Palette, Now Just £15! -
 立即领取
立即领取Myprotein UKPre-Workout £10 First 200 customers
Myprotein UKPre-Workout £10 First 200 customers
最新分享
更多-
 立即阅读
立即阅读统一链接平台来了!打破壁垒,支持跨设备、跨系统分享应用!
2024-11-14 18:15:02 -
 立即阅读
立即阅读第二代2K东方屏,一加13再创屏幕新巅峰
2024-11-14 18:05:03 -
 立即阅读
立即阅读主板CPU底座弯针、断针?微星售后免费帮你搞定!
2024-11-14 15:05:02 -
 立即阅读
立即阅读小米汽车发布智能底盘预研技术 能跳舞、原地和圆规掉头
2024-11-14 12:05:04 -
 立即阅读
立即阅读苹果因AirPodsPro杂音被起诉 或涉嫌虚假广告宣传
2024-11-14 11:05:02 -
 立即阅读
立即阅读“10”破天惊悟空屏!红魔10 Pro售价4999元起!
2024-11-14 10:25:17 -
 立即阅读
立即阅读蝉联大清洁品类第一!追觅科技“双11”业绩创新高,多平台领跑!
2024-11-14 10:20:03 -
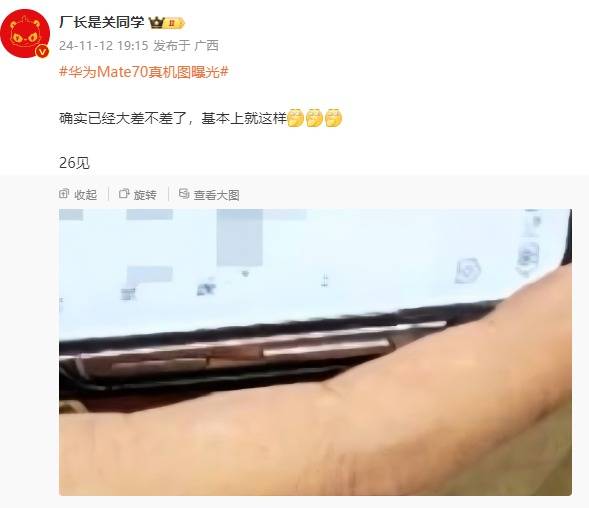 立即阅读
立即阅读华为Mate 70系列真机图曝光,或将于11月26日召开发布会
2024-11-14 10:15:05 -
 立即阅读
立即阅读苹果或明年初推出智能家居显示屏 6英寸方形设计外观类似iPad
2024-11-14 10:10:03 -
 立即阅读
立即阅读苹果或推多款智能家居产品 构建集成AI技术homeOS系统
2024-11-14 10:05:04